
前回の selenium で XPath を使うときのまとめも「基本編」の続きです。1つの記事にまとめようと思っていたのですがとっても長くなりそうだったので2つに分けました。

selenium で xpath を使って要素を取得するときの基本的なことは上記のまとめもに書いています。
本記事では狙った要素をバチッっと指定するための XPath の書き方をまとメモしています。
XPath は便利でいろいろなところで使われていますが、ここでは selenium で要素を取得することメインに考えて書いています!
python で selenium を使う場合にひとつ注意ポイントがあります。selenium のバージョンによって要素を見つけるために使う関数が若干異なります。
selenium 4.3.0 以降のバージョンでは WebDriver の find_element_by_* 関数と find_elements_by_ * 関数が廃止されたようです。
もし 4.3.0 以降のバージョンでこれらの関数を使うと、「AttributeError: ‘WebDriver’ object has no attribute ‘find_element_by_xpath’」系の例外が発生すると思います。
なので、特に python で、selenium の 4.3.0 以降のバージョンを使う場合は代わりに find_element 関数または find_elements 関数を使う必要があります。
新しい find_element 関数を使う場合は何で検索するか (クラスや xpath など) の部分を By をインポートして、引数で指定し、それらの検索方法に対応した値を第二引数 (オプション引数) 以降で指定するっぽいです。
以下は find_element 関数で Xpath による要素取得の場合です。
from selenium.webdriver.common.by import By
driver.find_element(by=By.XPATH, value="ここにxpath書く")Xpath そのものは以前の find_element_by_xpath 関数でも find_element 関数でも同じです!Xpath いいですねぇ!
XPath いろいろ
おもに省略形をのせています。
サンプルとして以下のような HTML を考えます。
<html lang="ja">
<head>
<meta charset="UTF-8">
</head>
<body>
<h1>長野県決勝戦</h1>
<div id="schools">
<h2>清澄高校</h2>
<div class="member">
<span class="tacos">片岡優希(1年)</span>
<span class="jihou">染谷まこ(2年)</span>
<span class="tyuuken">竹井久(3年)</span>
<span class="fukusyou">原村和(1年)</span>
<span class="taisho">宮永咲(1年)</span>
</div>
<div class="description">
<div>
<span>公立</span>
</div>
<div>
<span>共学</span>
</div>
</div>
<a href="http://www.saki-anime.com/">咲公式サイト</a>
</div>
</body>
</html>そして要素の取得できてるかの確認ソースコードはこれです!python です。
selenium 4.3.0 より前のバージョンの場合
elms = driver.find_elements_by_xpath("ここにXPathかく")
for i, elm in enumerate(elms):
print(f" --- {i} ---")
print(elm.get_attribute("outerHTML"))
print("")selenium 4.3.0 以降のバージョンの場合
from selenium.webdriver.common.by import By
elms = driver.find_element(by=By.XPATH, value="ここにXPath書く")
for i, elm in enumerate(elms):
print(f" --- {i} ---")
print(elm.get_attribute("outerHTML"))
print("")ファインドエレメンツで対象要素をすべて取得し for 文で回して要素の HTML を get_attribute(“outerHTML”) 関数でゲットして表示しています。
属性で指定
//タグ名[@属性=’属性の値’]
//span[@class=’tacos’]
span 要素で class が tacos であるもの。
selenium で実行すると、上記の HTML なら片岡優希のところの要素が取得できる。
//a[@href=’http://www.saki-anime.com/’]
a 要素で href が http://www.saki-anime.com/ であるもの。
//div[@class=’description’]/div
もちろん一部省略の途中のノードの条件にも使えます!この意味は class が description である div 要素の中の div 要素となります。この例の場合だと、公立や共学というテキストを囲む span 要素を含んだ div 要素が2つ取得できます。
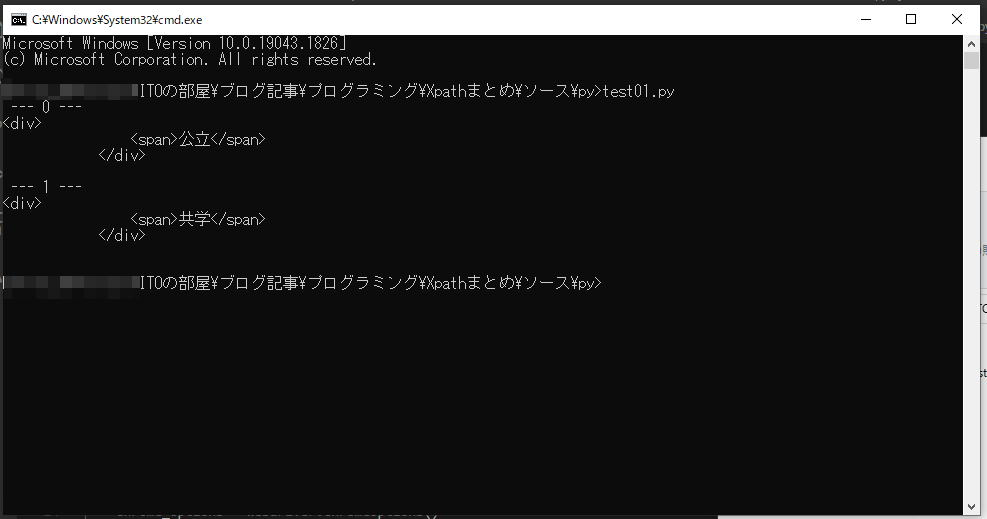
実際に python の selenium で取得してみた結果です。
タグ名と属性だけでもかなり絞れます!
順番系
//タグ名[数字]
//タグ名[position()=数字]
対象要素のうち何番目にあるものかを指定する。
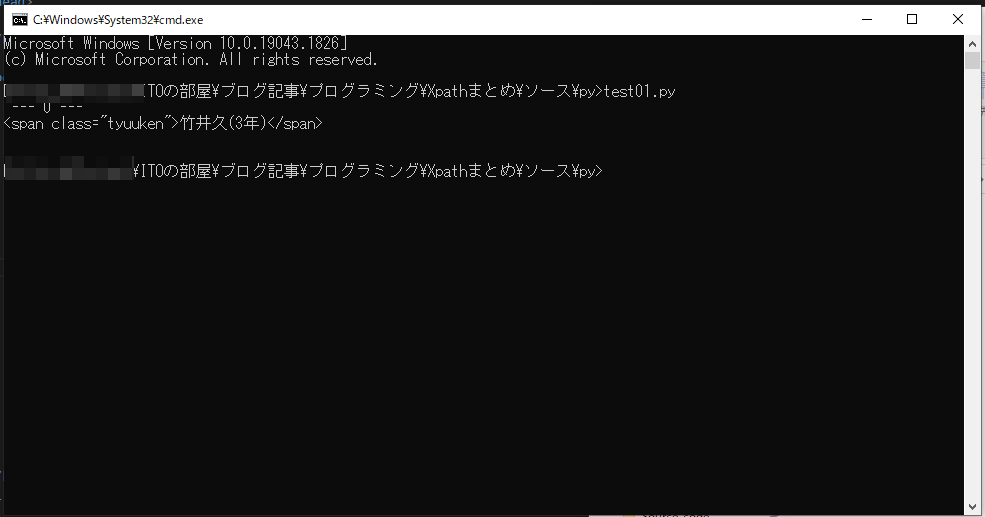
//div[@class=’member’]/span[3]
//div[@class=’member’]/span[position()=3]
これはどちらも同じ結果が得られます。class が member である div 要素の下の span 要素のうち3番目のものという意味になります。今回の例だとどちらの XPath を利用しても竹井久のところの span 要素が取得できます。
//タグ名[position()>数字]
対象要素のうち何番目より後ろにあるとか、何番目以下とかを指定。
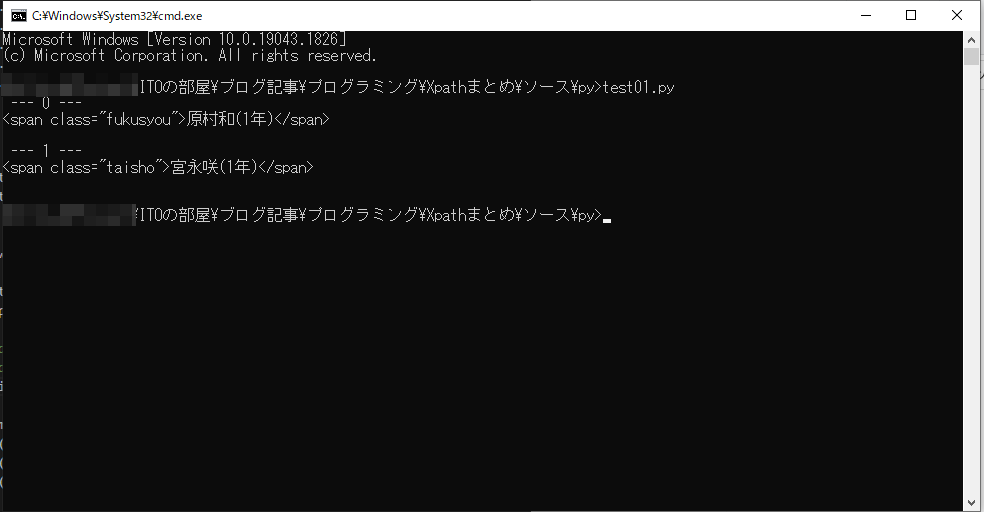
//div[@class=’member’]/span[position()>3]
意味は class が member である div 要素の下の span 要素のうち3番目より後のもの。今回の例だと条件にあう span 要素が5個あって、3番より後ろなので4番目と5番目が対象。つまり原村和と宮永咲の span 要素が取得できます!
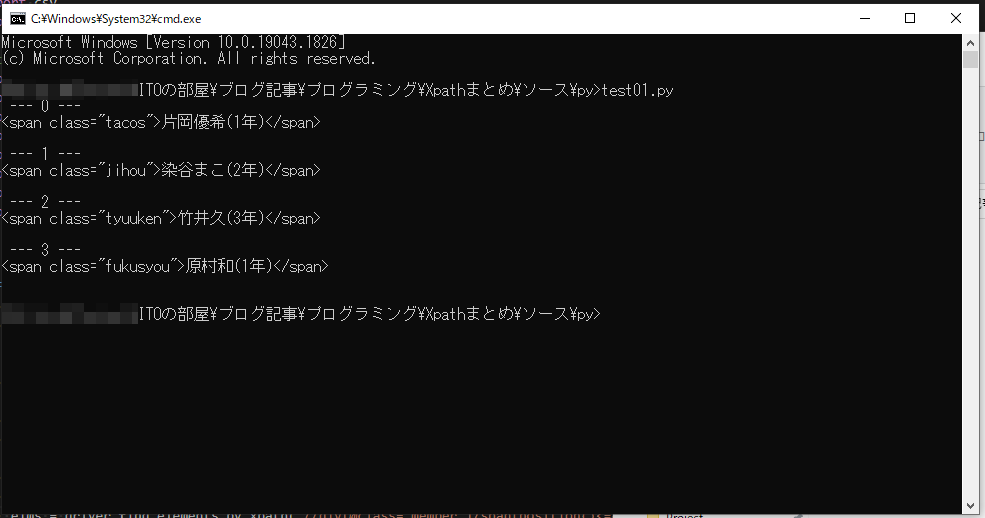
//div[@class=’member’]/span[position()<=4]
さっきのやつの「以下」バージョン。より大きい、より小さいだけでなく以上、以下の指定もオッケー。この場合は、対象 span の1番目、2番目、3番目、4番目が取得できます。「以下」なので4番目も含みます。
//タグ名[last()]
//タグ名[position()=last()]
何番目かは分からないけど最後を取得したい場合。最初が欲しいときは数字を1にすればいいのですが、最後が欲しいときは番号ではなく last でいけます。上記2つはどちらも同じ結果です。
//div[@class=’member’]/span[last()]
//div[@class=’member’]/span[position()=last()]
今の例だと、この xpath で 先ほどの selenium(python) を実行すると宮永咲の span 要素が取得できます。
テキストで指定
//タグ名[text()=’タグ内のテキスト’]
//span[text()=’片岡優希(1年)’]
span 要素で、要素内のテキストが片岡優希(1年)であるもの。この場合のテキストは完全一致です。含む系の部分一致は contains を使います。
含む系
テキストや属性の値について完全一致ではなく部分的に一致するものを探します。
//タグ名[contains(検索対象, 含むもの)]
検索対象にはさっき出てきた属性やテキストを利用します。
//span[contains(@class, ‘ou’)]
span 要素のうち class が ou を含むもの。今回だと「染谷まこ」と「原村和」の span 要素が取得できます。
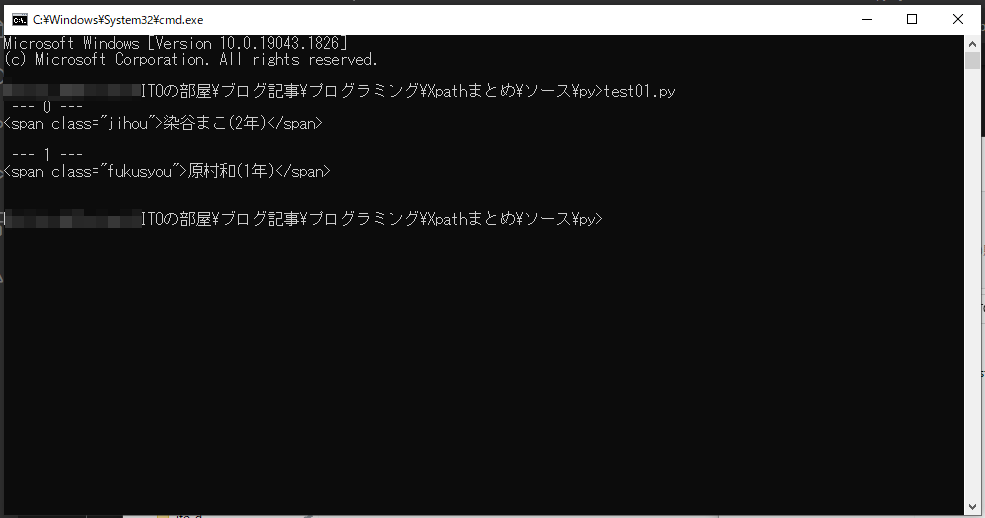
//span[contains(text(), ‘1年’)]
span 要素のうちタグ内のテキストに1年を含むもの。今回の例だと「片岡優希(1年)」と「原村和(1年)」と「宮永咲(1年)」の span 要素が取得できます。
//タグ名[starts-with(検索対象, 先頭のもの)]
含む系の先頭一致バージョン。
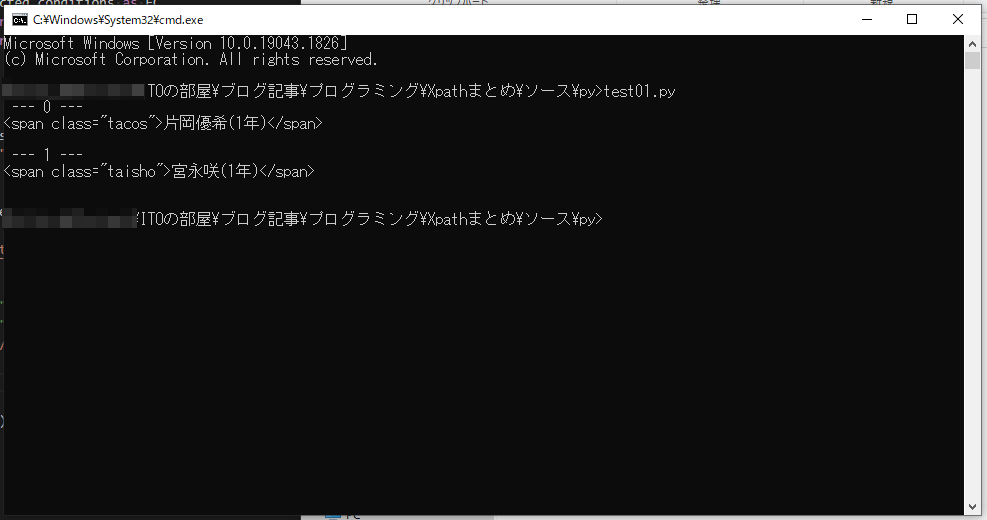
//span[starts-with(@class, ‘ta’)]
これの意味は span 要素のうち class が ta で始まるもの。なので、tacos と taisho が当てはまります。片岡優希と宮永咲の span 要素が取得できます。
論理演算
and、or、not などの論理演算も使えます。今までに登場した指定条件を組み合わせてばっちり要素を狙えます!
ここからはもう少し複雑 (長い) な以下の HTML を例として使います。
要素の取得チェックに用いる python コードはさっきと同じです。
<html lang="ja">
<head>
<meta charset="UTF-8">
</head>
<body>
<h1>長野県決勝戦</h1>
<div id="schools">
<h2>清澄高校</h2>
<div class="member">
<span class="tacos">片岡優希(1年)</span>
<span class="jihou">染谷まこ(2年)</span>
<span class="tyuuken">竹井久(3年)</span>
<span class="fukusyou">原村和(1年)</span>
<span class="taisho">宮永咲(1年)</span>
</div>
<div class="description">
<div>
<span>公立</span>
</div>
<div>
<span>共学</span>
</div>
</div>
<h2>龍門渕高校</h2>
<div class="member">
<span class="senpou">井上純(2年)</span>
<span class="jihou">沢村智紀(2年)</span>
<span class="tyuuken">国広一(2年)</span>
<span class="fukusyou">龍門渕透華(2年)</span>
<span class="taisho">天江衣(2年)</span>
</div>
<div class="description">
<div>
<span>私立</span>
</div>
<div>
<span>おそらく女子高</span>
</div>
</div>
<h2>風越女子</h2>
<div class="member">
<span class="senpou">福路美穂子 (3年)</span>
<span class="jihou">吉留未春 (2年)</span>
<span class="tyuuken">文堂星夏 (1年)</span>
<span class="fukusyou">深堀純代 (2年)</span>
<span class="taisho">池田華菜 (2年)</span>
</div>
<div class="description">
<div>
<span>私立</span>
</div>
<div>
<span>女子高</span>
</div>
</div>
<h2>鶴賀学園</h2>
<div class="member">
<span class="senpou">津山睦月 (2年)</span>
<span class="jihou">妹尾香織 (2年)</span>
<span class="tyuuken">蒲原智美 (3年)</span>
<span class="fukusyou">東横桃子 (1年)</span>
<span class="taisho">加治木ゆみ (3年)</span>
</div>
<div class="description">
<div>
<span>私立</span>
</div>
<div>
<span>女子高</span>
</div>
</div>
<a href="http://www.saki-anime.com/">咲公式サイト</a>
</div>
</body>
</html>//タグ名[条件 and 条件]
3大論理演算子のひとつアンド。
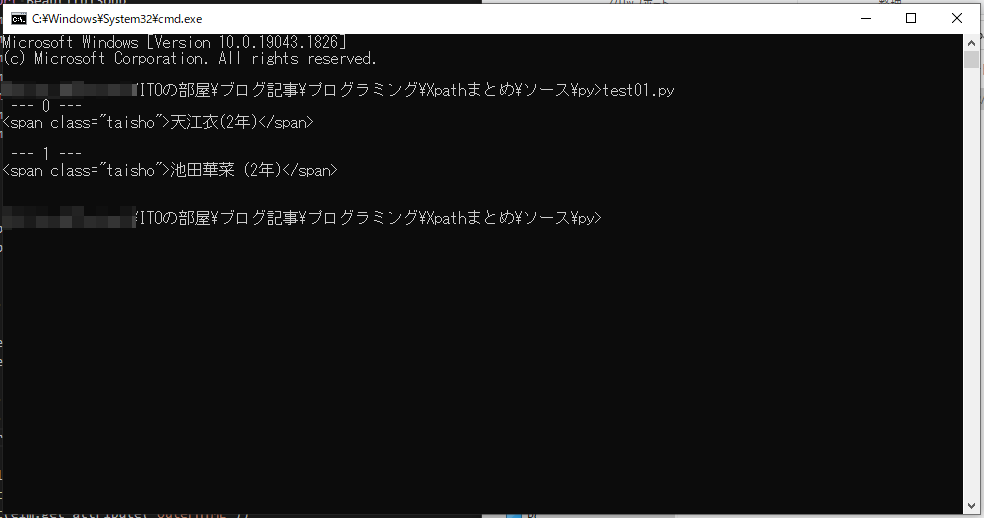
//span[contains(text(), ‘2年’) and @class=’taisho’]
かなり複雑そうな XPath になってきました。これの意味は span 要素のうちテキストに「2年」を含み、かつその要素の class が taisho であるもの。なのでこの例では、天江衣と池田華菜の span 要素がゲットできるはずです。
結果は以下です。
//span[contains(text(), ‘2年’) and @class=’taisho’ and contains(text(), ‘天’]
条件が3つでもいけます。さっきの例の条件に「テキストに天という文字を含む」という条件を and で付け加えて実行すると、ちゃんと天江衣のとろこの span 要素のみ取得できました。
//タグ名[条件 or 条件]
3大論理演算子のひとつオアー。
//span[contains(text(), ‘2年’) or @class=’taisho’]
and のところで紹介した例の or バージョン。span 要素のうちテキストに「2年」を含む、または、要素の class が taisho であるもの。結果は以下の通りです。
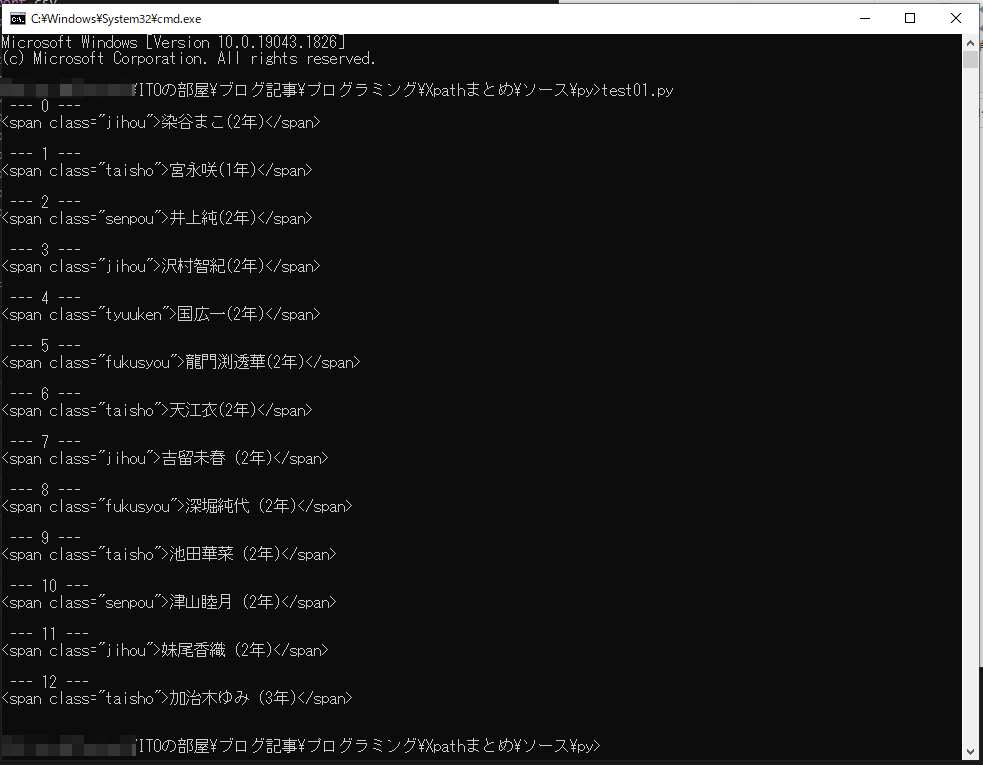
//タグ名[not(条件)]
3大論理演算子の最後の1つノット。
//div[@class=’member’]/span[not(position()=4)]
ノットの条件のとろこに順番系で紹介した position を入れてます。この XPath の意味は、class が member である div 要素の中の span 要素のうち4番目の要素ではないもの。この例では4番目つまり副将の選手以外の span 要素を取得できます。
XPath もっといろいろ!
今まで登場した Xpath よりも少し発展系のものです。
selenium (python) での取得チェックに使う HTML はさっきと同じ長野県インターハイ県予選団体戦決勝の出場校のやつです!
入れ子系
名前は私が勝手に読んでいるだけなので正式な呼び名は違うかもしれません。
今まで角カッコ [] の中には位置とか属性とか含むとかの条件しか書いてませんでしたが、要素 (タグ名) そのものを書いて入れ子のようにすることもできます。入れ子にした要素にさらに角カッコで条件指定もできます。
//タグ名[タグ名[条件いろいろ]]
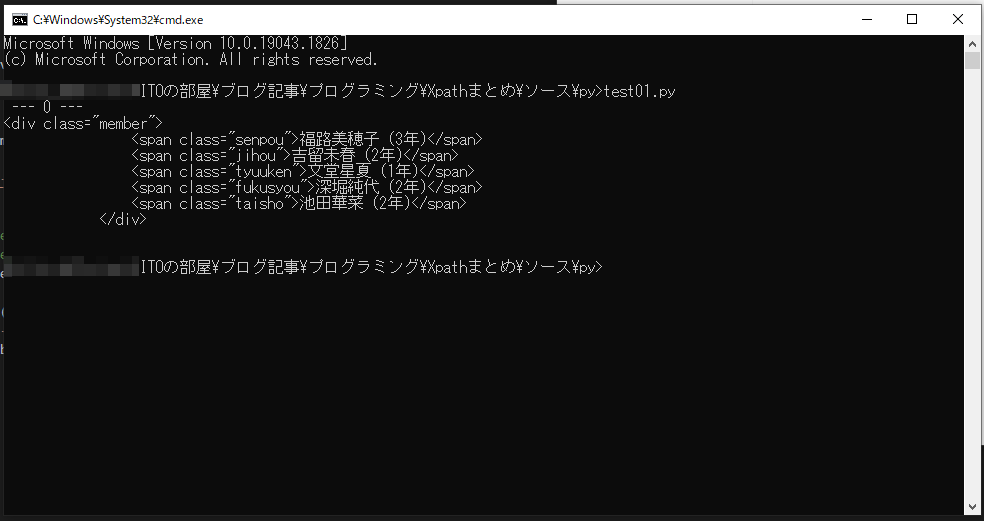
//div[span[contains(text(), ‘福路美穂子’)]]
これまたややこしいですが、じっくり見ていきましょう。角カッコの中に要素を書いていますが、あくまで角カッコ中なので条件です。この XPath で取得するのは div 要素です。
これは 「div 要素のうち、その要素の中の span 要素のテキストに福路美穂子が含まれるもの」という意味になります。
ですので風越女子のメンバーを記述している部分の div 要素が取得できます。
軸系
XPath ではタグ名の前に軸と呼ばれるそのノードとの関係 (親とか子とか) を表す情報を付加することができます。
そして、今までタグ名と呼んでいた部分は XPath の世界ではノードテストと呼ばれており、条件と呼んでいた角カッコの部分も述部と呼ばれています。
なのでスラッシュでつなぐ各ノードは実は以下のような構成になっています。
軸::ノードテスト[述部]
今までは基本的に軸を省略していました。
これらをつなげたものも実はロケーションパスと呼ばれています。
/軸::ノードテスト[述部]/軸::ノードテスト[述部] …
//軸::ノードテスト[述部]
//ノードテスト/軸::ノードテスト[述部]/ノードテスト/ノードテスト…
ですが、本記事では今まで通りの呼び方でいきます!ただ、軸だけは軸と言います(笑)
軸のうちよく使う関係のものを例を出してメモします。
//span[contains(text(), ‘福路美穂子’)]/parent::div
//span[contains(text(), ‘福路美穂子’)]/parent::node()
parent。文字通り親要素を指します。この例の XPath の意味はテキストに福路美穂子を含む span 要素の親要素です。対象の親要素が div だと分かっている場合は1つ目の例のように軸の後に div と書きます。親要素のタグ名が分からない場合は2つ目の例のように node() と書けばオッケーです。
この2つの例はどちらも同じ結果となります。しかも、先ほどの入れ子系の例と同じ結果です!
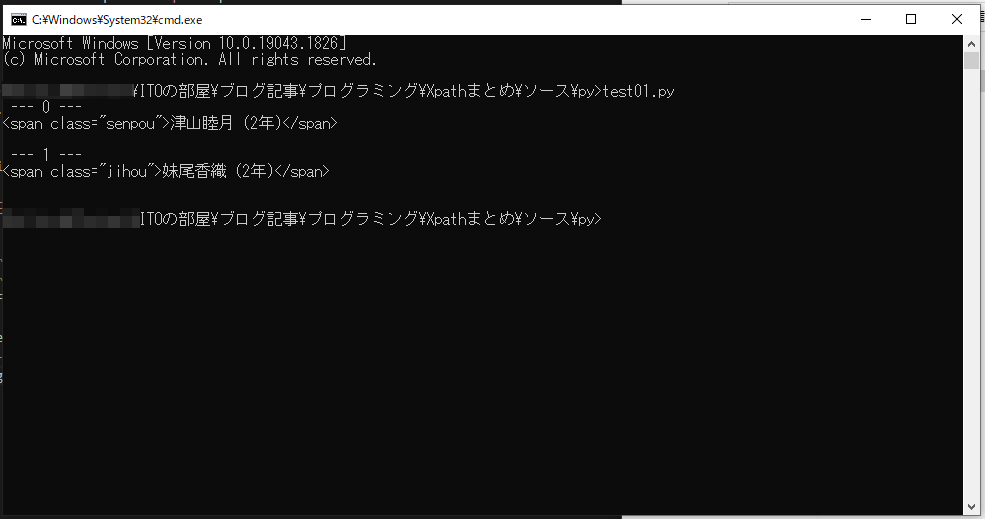
//span[contains(text(), ‘蒲原智美’)]/preceding-sibling::span
兄弟要素を取得するのに便利です。前の (preceding) 兄弟 (sibling) ということで、自分自身より前にある兄弟要素をすべて取得できます。
この例の XPath の意味は「テキストに蒲原智美を含む span 要素の兄弟要素のうち前にあるものすべて」です。津山睦月と妹尾香織の span 要素が取得できるはず!
結果は以下です。
また、selenium で preceding-sibling::node() とするとエラーになる場合があるので、もしエラーになっている場合はタグ名を確認して記述してみてください。他の軸指定においても基本的にはタグ名を記述した方がいいかもです。
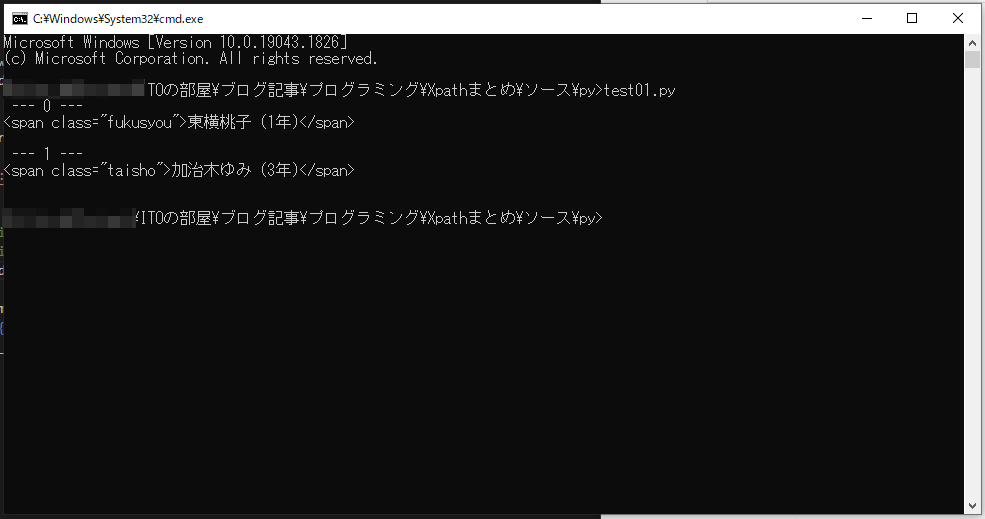
//span[contains(text(), ‘蒲原智美’)]/following-sibling::span
さっきの前の兄弟要素とは逆で、あとの (following) 兄弟要素を取得します。なので東横桃子と加治木ゆみの span 要素が取得できます!
エックスパスをいろいろメモメモしました。
これでバッチリ要素を取得していきます!


コメント