
おはようございます。ITO です。
最近は情報社会ですね。情報社会といえばパスワードロックです。
パスワードといえば、最近パスワードロックされた PDF が多くなってきたように感じます。パスワードロック解除を Python でもやりたいです。
Python で PDF を扱う場合に有名なライブラリで PyPDF2 というのがあります。非常に素晴らしいライブラリで Python で PDF に対していろいろな操作ができます。
もちろんパスワードをかけたり、ロック解除したりもできます。しかし、、、PDF の暗号化の方法が AES だった場合ロック解除が今まではできませんでした。
ところが、2022年6月19日リリースの Version 2.3.1 で可能になったらしいのです!
今回はその PyPDF2 で AES で暗号化された PDF を扱うときのメモです。
インストールに注意
PyPDF2 で AES 暗号化された PDF のパスワード解除 (復号) するときに最も気を付けなければならないのが pip でインストールするときです!
インストールするには
pip install PyPDF2[crypto]
このように [crypto] とオプションのようなものを付けてインストールする必要があります。
“のようなもの”と表現したのには訳あって pip でオプションといったら普通は -U とか -r とかを指すからです。
PyPDF2 公式ドキュメントでは 「Optional dependencies」となっているので直訳してオプション依存関係と呼べばいいのかな。。。
Optional dependencies
PyPDF2 公式ドキュメント – installation
PyPDF2 tries to be as self-contained as possible, but for some tasks the amount of work to properly maintain the code would be too high. This is especially the case for cryptography and image formats.
上が公式ドキュメントです。
要約・意訳すると、「PyPDF2 はできる限り自己完結を目指しているが、暗号化や画像を扱うための処理のソースコードメンテがかなり大変なので追加のライブラリの力を借りている」というということでしょうか。
ということは、画像や暗号を扱う場合は追加の依存ライブラリが必要であり、必要な人だけ付加してインストールするためのオプションっぽいです。不要なものは付けずに軽量化するってのはなかなか合理的です。
ちなみに pip の公式ドキュメントではこのような [ ] 付きのインストールを「Install a package with extra」と表現しているので日本語で話すときは、追加とか予備とか言えばいいのかもしれません。

実行時の違い
追加の依存ライブラリオプションなしでインストールした PyPDF2 とありでインストールした PyPDF2 とでは AES で暗号化された PDF を復号しようとしたときの挙動が異なります。また、なしの場合でも AES の種類が 128bit なのか 256bit なのかでも若干挙動が異なりました。
違いの確認に使ったソースは以下です。パスワードは正しいものを入力します。
import PyPDF2
def difference():
filename = "テスト文書_暗号化あり.pdf"
password = "123456"
# PdfFileReaderオブジェクト作成
pfr = PyPDF2.PdfFileReader(filename)
# PDFが暗号化されているかの確認
print(f"Is encrypt: {pfr.isEncrypted}")
# パスワードを入力した結果
print(f"return: {pfr.decrypt(password)}")
for key in pfr.documentInfo.keys():
print(f"{key}: {pfr.documentInfo[key]}")PDF が暗号化されているかの確認と、パスワードの解除 (復号) を試みています。その後ファイルのメタデータを表示しています。復号するための PdfFileReader オブジェクトの decrypt 関数の戻り値は次の表の通りです。
| Return | 意味 |
|---|---|
| 0 | パスワードが違うよ |
| 1 | ユーザーパスワードと一致 |
| 2 | オーナーパスワードと一致 |
[crypto] ありインストール・256-bit AES
![[crypto] ありインストール・256-bit AESの実行結果画像](https://ito-room.com/wp-content/uploads/2022/11/0001_yes_256.png)
追加依存ありなのでしっかり復号と中身の読み取りも出来ているようです。戻り値が2となっておりオーナーパスワードと一致してファイルを開くことができています。なのでファイルのメタデータも確認できます!
[crypto] なしインストール・256-bit AES
![[crypto] なしインストール・256-bit AESの実行結果画像](https://ito-room.com/wp-content/uploads/2022/11/0002_no_256.png)
最初の PDF が暗号化されているかの確認の時点でエラー (例外) が発生しています。やはり追加依存ライブラリなしのインストールでは AES で暗号化された PDF は扱えないようです。
例外のメッセージにも 「AES アルゴリズムが必要だよ!」と出ています。
[crypto] ありインストール・128-bit AES
![[crypto] ありインストール・128-bit AESの実行結果画像](https://ito-room.com/wp-content/uploads/2022/11/0003_yes_128.png)
先ほどの 256-bit AES のときと同様ちゃんと復号&メタデータ確認ができています。
[crypto] なしインストール・128-bit AES
![[crypto] なしインストール・128-bit AESの実行結果画像](https://ito-room.com/wp-content/uploads/2022/11/0004_no_128.png)
なしの場合の 256-bit AES と同じ結果になると思っていたらちょっとだけ違ってました。
暗号化されているかの判定とパスワードが正しいのかどうかまでは出来ました!その後メタデータを読み出そうとするとエラーになってしまいました。
例外のメッセージには 256-bit AES のときと同様「AES アルゴリズムが必要ぜよ」が出ています。
実行してみる
何はともあれ、今時の PDF 暗号化といえば AES が使われていると思うので PyPDF2 で暗号化についての処理を扱う番号は追加依存オプションありでインストールすればオッケーです。
すでにロック解除の関数などを少しのせていますが、改めてロック解除 (復号) とパスワードロックを設定 (暗号化) について書きます。
ロック解除 (復号)
ここでやりたいことは「パスワードロックがかかった PDF (暗号化された PDF) をパスワードがかかっていない状態にする」とします。
元のファイルを消してしまうと万が一データが破損してしまったときに泣くので元のファイルは置いときます。
なので以下のステップでやります。
- 暗号化された PDF を読み込む
- パスワードロック解除!
- 複製を作ってパスワードなしで保存
ソースコード
ソースコードは以下です。
import PyPDF2
def MyDecryptPDF():
filename = "テスト文書_暗号化あり.pdf"
password = "123456"
# PdfFileReaderオブジェクト作成
pfr = PyPDF2.PdfFileReader(filename)
# PDFが暗号化されているかの確認
print(f"Is encrypt: {pfr.isEncrypted}")
# パスワードを入力した結果
result = pfr.decrypt(password)
print(f"return of decrypt(): {result}")
## パスワード解除に成功した場合のみ複製保存を実行
if result == 1 or result == 2:
''' decrypt()の戻り値が 1 or 2 の場合はパスワードあってる! '''
# PdfFileWriterオブジェクト作成(書き込み用)
pfw = PyPDF2.PdfFileWriter()
# 書き込み用オブジェクトに複製をコピー
pfw.clone_reader_document_root(pfr)
# 新しいファイル名(hoge.pdf -> hoge_decrypted.pdf)
new_filename = filename.rsplit(".", 1)[-2] + "_decrypted.pdf"
# 保存
pfw.write(new_filename)
else:
''' decrypt()の戻り値が 0 の場合はパスワードが間違ってる '''
return -1
return 0PdfFileReader オブジェクトの decrypt 関数の戻り値以下の表の通りです!さっき上でも載せましたがもう一度!
| Return | 意味 |
|---|---|
| 0 | パスワードが違うよ |
| 1 | ユーザーパスワードと一致 |
| 2 | オーナーパスワードと一致 |
PDF は 2 段式でファイルの保護ができて、パスワード解除した者に、主に PDF の閲覧だけを許すユーザーパスワード (文書を開くパスワード)、閲覧に加えて編集や印刷などすべての操作が許されるオーナーパスワード (マスターパスワード) と出来ることに合わせた2種類のパスワードがある。
設定次第では、両方のパスワードが設定されていてもユーザーパスワードだけで印刷や変更も可能。
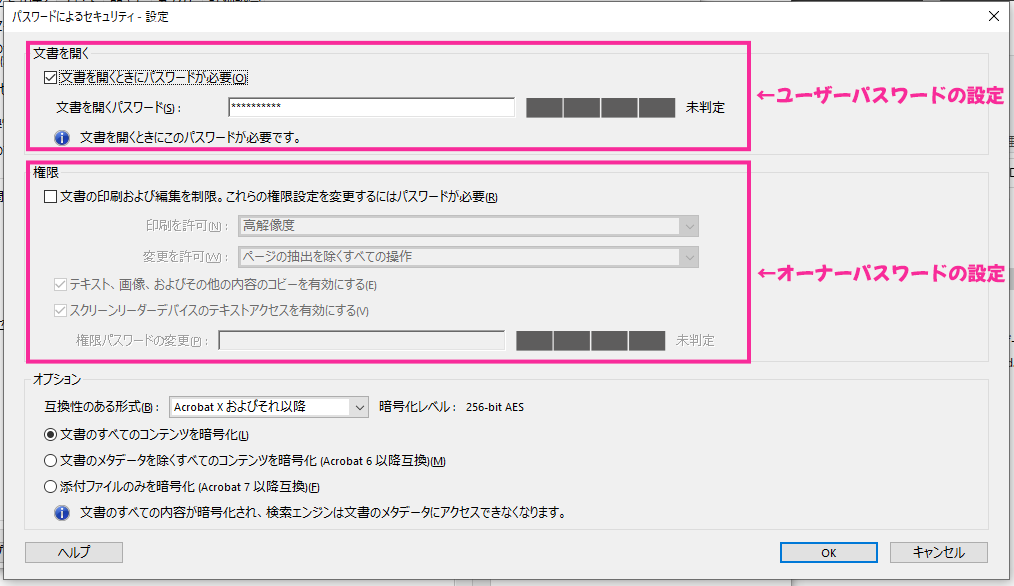
decrypt 関数の戻り値を判定してパスワードが開いた場合のみ複製と保存処理を行います。
複製には PdfFileWriter オブジェクトの clone_reader_document_root 関数を使っています。ほぼ同じ機能&名前の cloneReaderDocumentRoot 関数というのもあるんですが、公式によると今は非推奨になっているようです。

保存の際のファイル名は元のファイル名のベースネーム (呼び方あってる?) の部分に _decrypted を付けたもの。拡張子は同じく .pdf です。
○○○.pdf → ○○○_decrypted.pdf
あと、暗号化されていない PDF を読み込んで decrypt 関数を呼び出すと例外 (PyPDF2.errors.PdfReadError: Not encrypted file) が発生するので暗号化されていない PDF が読み込まれる可能性があるなら、isEncrypted をもとに条件分岐とかした方がいいかもです。

コメント