
今年も夏本番といった感じになってきました。熱い夏はキンキンに冷えたそうめんを食べながら web スクレイピングをすることがあると思います。
私もよくあります。そんなときによく python で selenium というライブラリを使ってやっています。
そして xpath で web サイトの要素を指定するときに書き方を忘れては検索、忘れては検索を繰り返しているので、どんなに忘れてもいいようにここにメモします。
selenium で XPath
最近 selenium で要素指定するときはほとんど xpath に頼っています。理由はいくつかありますが、なによりスクレイピングするときの言語が変わってもオッケーというのがデカいです!
私はおもに python か c# でスクレイピングをしてます。selenium の書き方に若干の違いがあっても、xpath 自体は同じなので便利です。
XPath は selenium のためだけのものではありませんが、ここでは selenium での使用をメインに考えて書いています。
selenium 4.3.0 以降のバージョンでは WebDriver の find_element_by_* 関数と find_elements_by_ * 関数が廃止されたようです。
なので、特に python で、selenium の 4.3.0 以降のバージョンを使う場合は代わりに find_element 関数または find_elements 関数を使う必要があります。
新しい find_element 関数を使う場合は何で検索するか (クラスやxpathなど) の部分を By をインポートして、引数で指定し、それらの検索方法に対応した値を第二引数以降で指定するっぽいです。
以下は find_element 関数でXpath による要素取得の場合です。
from selenium.webdriver.common.by import By
driver.find_element(by=By.XPATH, value="ここにxpath書く")Xpath そのものは以前の find_element_by_xpath 関数でも find_element 関数でも同じです!Xpath いいですねぇ!
python のとき
パイソンでエックスパスを使うときです。driver は webdriver オブジェクトです。
selenium 4.3.0 より前のバージョンの場合
driver.find_element_by_xpath("ここにxpath書く")selenium 4.3.0 以降のバージョンの場合
driver.find_element(by=By.XPATH, value="ここにxpath書く")上のコードだと条件にあう要素で一番初めに見つかったもののみ取得します。
条件に合致する要素すべてを取得したい場合は複数形のエレメンツになったやつを使いましょう。
selenium 4.3.0 より前のバージョンの場合
driver.find_elements_by_xpath("ここにxpath書く")selenium 4.3.0 以降のバージョンの場合
driver.find_elements(by=By.XPATH, value="ここにxpath書く")C# のとき
シーシャープでエックスパスを使うとき。
driver.FindElement(By.XPath("ここにxpath書く"));同じく複数の要素を取得したいときはエレメンツ。
driver.FindElements(By.XPath("ここにxpath書く"));XPath きほんメモ
基本
書き方の基本は「取得したい要素までタグ名をどんどんスラッシュ ( / ) で繋げていく」です。
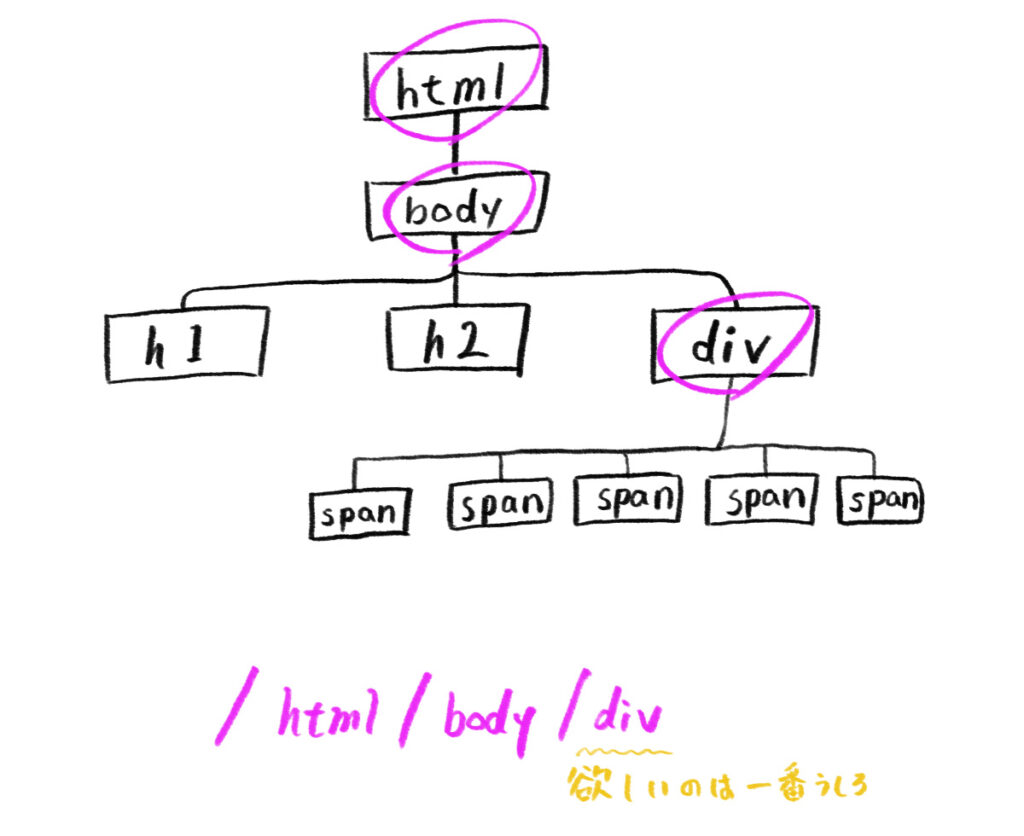
以下のような HTML があります。
<html>
<body>
<h1>長野県決勝戦</h1>
<h2>清澄高校</h2>
<div class="member">
<span class="tacos">片岡優希(1年)</span>
<span class="jihou">染谷まこ(2年)</span>
<span class="tyuuken">竹井久(3年)</span>
<span class="fukusyou">原村和(1年)</span>
<span class="taisho">宮永咲(1年)</span>
</div>
</body>
</html>div 要素を指定したければ
/html/body/div
とかきます。
ピンポイントで指定するための条件
さっきの HTML で span 要素を指定したい場合は
/html/body/div/span
と書けばオッケーなのですが、これだと div の下にある span のうち1番初めに発見されたものか、span すべてを取得します。(selenium の関数によって変わります)
なんで、もし5番目の span 要素 (宮永咲) を取得したいと思ったときはもう少し詳しく xpath を書く必要があります。
詳しく書くといっても簡単です!エックスパスは素晴らしい。
タグ名のよこに角カッコ [] で検索条件を書きます。
上記の HTML の div 要素の下の5番目の span 要素 (宮永咲のところ) を取得したい場合は
/html/body/div/span[@class=’taisho’]
でいけます。
これの意味は「html の中の body の中の div の中の span 要素で、class が taisho であるもの」です。
こんな感じで各要素の属性で条件を細かく指定できます。もちろん class だけでなく id や href などの他の属性でもいけます。
ちなみに、python や C# の selenium で xpath を書くとき xpath は文字列なのでダブルクォート (“) もしくはシングルクォート (‘) で囲む必要があります。そして先ほど出てきた各要素の属性の値もダブルクォートかシングルクォートで囲まないといけません。
このとき、外側のクォート (文字列リテラルを表現するため) と内側のクォート (属性の値を囲むやつ) が同じクォートだとプログラミング言語のエラーになる可能性があるので、内側と外側のクォートは異なるものにしましょう!
# 文字列リテラルをダブルクォートで表現しているので属性の値はシングルクォート
driver.find_elements_by_xpath("/html/body/div/span[@class='taisho']")
# 文字列リテラルをシングルクォートで表現しているので属性の値はダブルクォート
driver.find_elements_by_xpath('/html/body/div/span[@class="taisho"]')これは python の例。このようにエックスパス自体の文字列をダブルクォートで囲んでいるなら、属性の値はシングルクォートで囲む。逆に文字列をシングルクォートで囲んでいるなら属性の値はダブルクォートで囲む感じです!
省略した書き方
今まで書いてきた XPath は省略して記述することができます。ちょっと長いな~って思ってたのでありがたいです(笑)
さっきの宮永咲の要素を取得するエックスパスなら以下のように省略できます。
/html/body/div/span[@class=’taisho’]
↓
//span[@class=’taisho’]
ラクです!かなり短いです。
省略しない場合は「 / 」で始まりトップの html から順番に全部書いていましたが、「 // 」で始めることで途中のノードを省略できます。
あくまで途中のノードの省略なので最終の要素1つだけを書かないといけないわけじゃないです。一部省略的なこともオッケーです。
なので!上記の HTML において下の3つの XPath は同じものを取得できます。
/html/body/div/span[@class=’taisho’]
//div/span[@class=’taisho’]
//span[@class=’taisho’]
省略するときの注意点
省略はとっても便利ですがその分指定が難しくなることもあります。
<html lang="ja">
<head>
<meta charset="UTF-8">
</head>
<body>
<h1>長野県決勝戦</h1>
<h2>清澄高校</h2>
<div class="member">
<span class="tacos">片岡優希(1年)</span>
<span class="jihou">染谷まこ(2年)</span>
<span class="tyuuken">竹井久(3年)</span>
<span class="fukusyou">原村和(1年)</span>
<span class="taisho">宮永咲(1年)</span>
</div>
<div class="description">
<div>
<span>公立</span>
</div>
<div>
<span>共学</span>
</div>
</div>
</body>
</html>このような HTML があります。
このときエックスパスを
//span
として selenium で find_elements_by_xpath を実行すると7個の要素が取得できます。
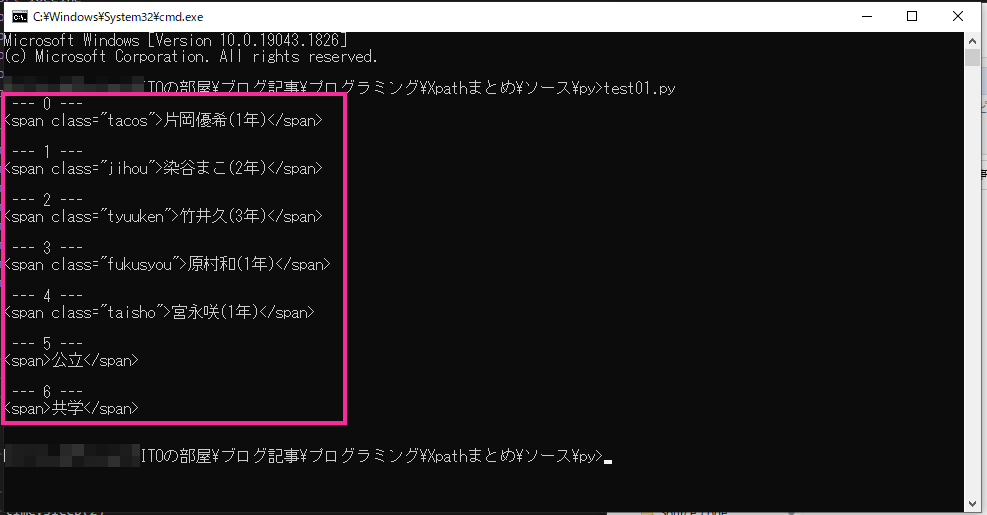
こんな感じです。selenium で取得した要素リストを for 文で回して表示しました。selenium の element オブジェクトの get_attribute(“outerHTML”) で要素の HTML を確認しています。
elms = driver.find_elements_by_xpath("//div/span[@class='taisho']")
for i, elm in enumerate(elms):
print(f" --- {i} ---")
print(elm.get_attribute("outerHTML"))
print("")部のメンバーの部分を表す省略なしの xpath は
/html/body/div/span
で、共学とか公立のとかの要素のところの省略なしの xpath は
/html/body/div/div/span
となります。「 //span 」だけだとどっちも対象になります。
省略したらその分曖昧になるということなので、狙った要素をバチッとしていするためには角カッコで詳しく条件を指定したり、末端までのすべてのノードを省略せずに一部省略とかをうまく使わないとあかんです。

↑こちらの記事で狙った要素を取得するための XPath をいろいろメモしています。


コメント